Paper Reading: Neural Architecture Search with Reinforcement Learning
Published:
Neural Architecture Search with Reinforcement Learning
Conference: ICLR 2017
Author: Barret Zoph, Quoc V. Le (Google Brain)
相关工作
- 超参优化: (NAS本质上是一种非欧空间的超参优化问题). 他们只能在固定长度的空间搜索模型. 已有贝叶斯优化方法可以搜索非定长的结构(文中引用Bergstra 2013 [1]: 我没看出来这篇文章为啥可以搜索变长结构), 但是它们不一般化和灵活.
- note: 另一篇工作Auto-Keras[2]: 利用Graph Kernel(Edit-Distance Neural Network Kernel)作为Gaussian Process的核函数衡量两个神经网络的相似度来搜索非定长的神经网络结构
- 神经进化算法: 在组成新模型上更灵活, 但是通常在大规模上缺少实用性. 由于它们是基于搜索的方法, 因此很慢或需要启发式策略来达到好的效果.
- 神经网络架构搜索: 与程序合成和归纳编程相似. 神经网络架构搜索的控制器是自回归的(auto-regressive), 它们每次迭代基于之前的预测结果来预测下一组超参数.
强化学习
之前对强化学习只是知道有这个东西, 感觉又是个大坑.
强化学习的思想和人类很类似, 不停的通过环境的反馈来更新决策.
监督学习每个输入对应一个输出, 而强化学习是延后给出的, 它只会在每次决策之后给出一个奖励值.
强化学习可以在探索和开发(exploration and exploitation)之间做权衡以得到最大的回报, 而一般的监督学习算法只是exploitation.
一些常用概念:
- 动作Action: agent可以做的所有可能行动
- 状态State: 环境返回的当前状态
- 奖励Reward: 环境的即时返回值, 评估上一个动作
目标就是获得最多的累计奖励.
本文中应用的技术是Policy Gradient.
Policy Gradient Theorem(episodic):
本文用到的是REINFORCE方法(也就是Monte-Carlo policy gradient), 利用上面的定理:
- 随机初始化参数$\theta$
- 根据$\pi(.|., \theta)$生成一个episode $S_0, A_0, R_1, \dots, S_{T-1}, A_{T-1}, R_T$
- for $t = 0, 1, \dots, T-1$
- 估计$G_t=\sum_{k=t+1}^{T} \gamma^{k-t-1} R_{k}$
- 更新$\boldsymbol{\theta} \leftarrow \boldsymbol{\theta}+\alpha \gamma^{t} G \nabla \ln \pi\left(A_{t} | S_{t}, \boldsymbol{\theta}\right)$
模型
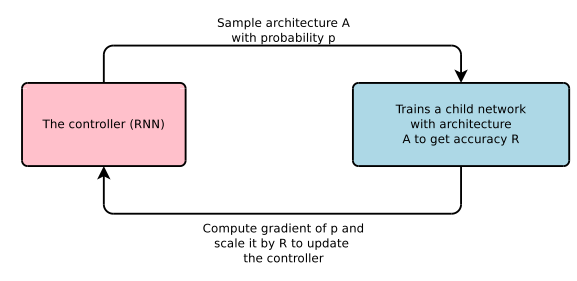
将神经网络结构描述为变长的字符串, 每次迭代用一个控制器RNN来生成这个字符串, 然后得到对应网络结构的准确率作为奖励信号(reward), 计算策略梯度(policy gradient)来更新控制器.
生成网络结构
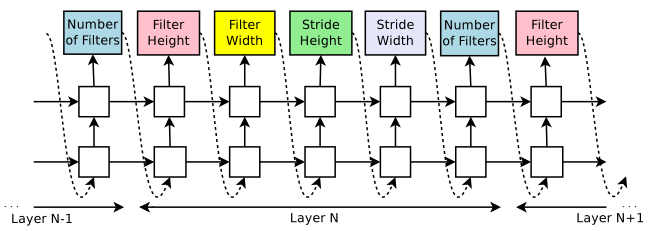
假设只有CNN, 当层数达到一个阈值,就会停止. 通过强化学习更新RNN的参数$\theta_c$
训练
控制器产生的一组token看为是一组actions, 在验证集上的准确率为reward. 通过REINFORCE方法:
上面的作法是一个无偏估计但是有很大的方差, 为了减小方差variance引入了一个baseline函数b(这也是一个常见做法,见Reinforcement Learning: An Introduction [3], Section 13.4):
在这里b是之前的结构的准确率的指数移动平均.
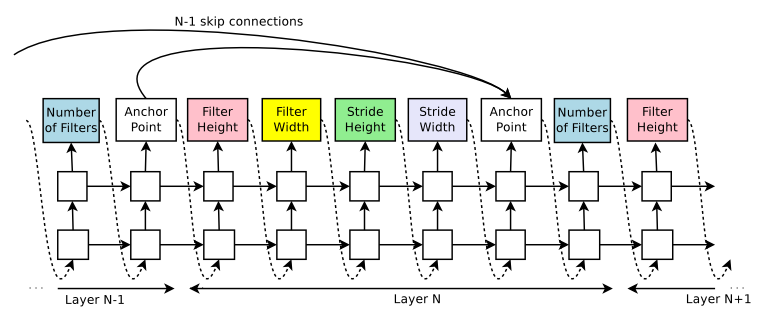
为了加入类似resnet的skip connections, 每一层加入一个anchor points, 控制是否和之前的层相连(set-selection attention):
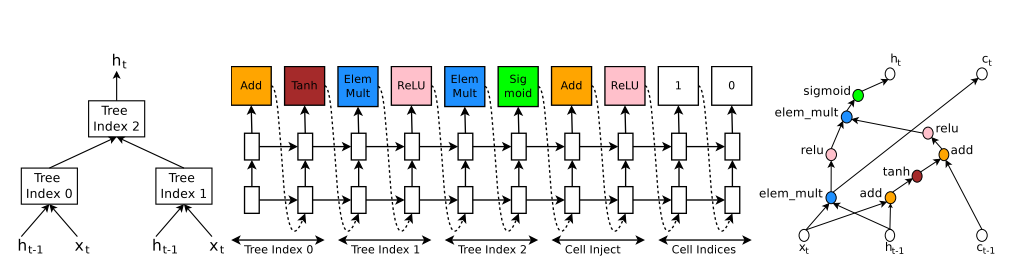
为了生成RNN结构, 引入树结构输入$x_t, h_{t-1}$, 输出$h_t$. 类似LSTM还引入了记忆变量输入$c_{t-1}$输出$c_t$.
总结
文章用RNN来生成神经网络结构, 并用REINFORCE来更新参数, 能够搜索变长的结构空间.
但是感觉用一个序列的方式生成一个网络还是不够灵活, 以及这个算法太耗时了(文中用800个GPU训练了好几天, 穷人玩不起…).
[1] James Bergstra, Daniel Yamins, and David D Cox. Making a science of model search: Hyperpa- rameter optimization in hundreds of dimensions for vision architectures. ICML, 2013.
[2] Jin, Haifeng, Qingquan Song, and Xia Hu. “Efficient neural architecture search with network morphism.” arXiv preprint arXiv:1806.10282 (2018).
[3] Sutton and Barto. “Reinforcement Learning: An Introduction” 2018.